Reasoning VQA by Giving Reasons to Support the Predictions
The topic will have a statistical and mathematical context. Good knowledge of Matlab/Caffe/Tensorflow/Python programming is plus. Basic knowledge of CV and NLP is also needed.
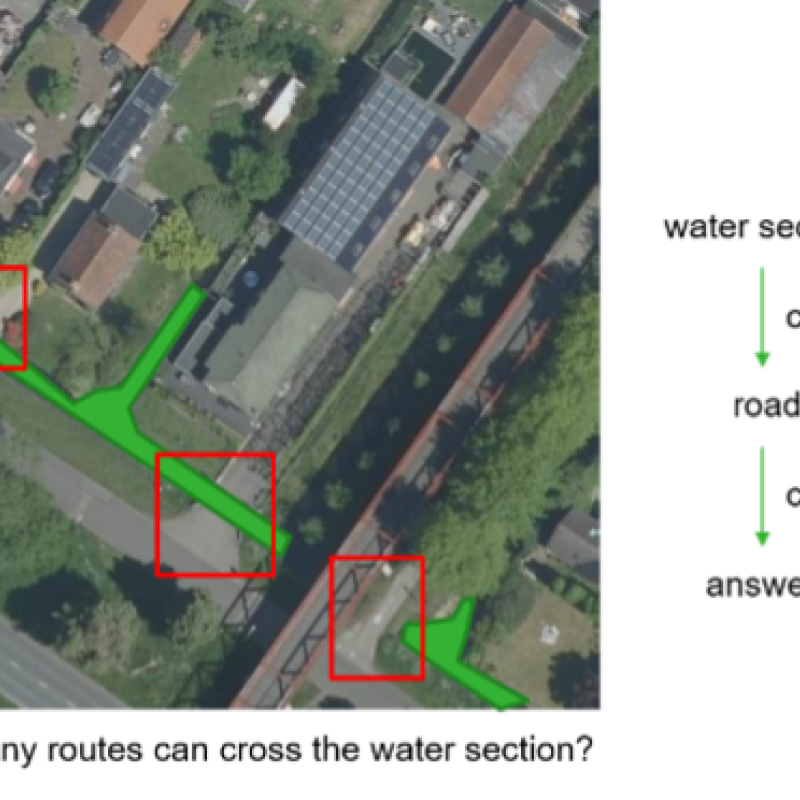
In this project, we plan to address the problem of reasoning the visual question answering process when predicting the answers to the given image/question pairs. This problem solved could serve as a real artificial system to explain how the VQA models think, and provide more convincing answers. The more difficult the questions are, the more complex thinking and more detailed reasoning is needed. In this settings, high-resolution aerial images with labeled question/answer pairs from some available datasets are really suitable for this task, from simple questions such as attribute recognition to hard questions such as vehicle moving activities.
The project will require a well-designed VQA system with the capability of good reasoning, and some knowledge bases for high-level questions with corresponding geo-information. Deep learning will play an important role in this topic, including the techniques from computer vision, natural language processing, and remote sensing. Pre-trained models based on CNN and transformer will be applied to the learning stages.
1. Zellers, R., Bisk, Y., Farhadi, A., & Choi, Y. (2019). From recognition to cognition: Visual commonsense reasoning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 6720-6731).
2. Cadene, R., Ben-Younes, H., Cord, M., & Thome, N. (2019). Murel: Multimodal relational reasoning for visual question answering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 1989-1998).
3. Lobry, S., Marcos, D., Murray, J., & Tuia, D. (2020). RSVQA: Visual question answering for remote sensing data. IEEE Transactions on Geoscience and Remote Sensing, 58(12), 8555-8566.
4. Bendre, N., Desai, K., & Najafirad, P. (2021, October). Show why the answer is correct! towards explainable ai using compositional temporal attention. In 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC) (pp. 3006-3012). IEEE.